A Playbook for Surviving Production Outages
What you'll learn
 Incident Response StructureRapid Service RestorationRoot Cause AnalysisContinuous Improvement
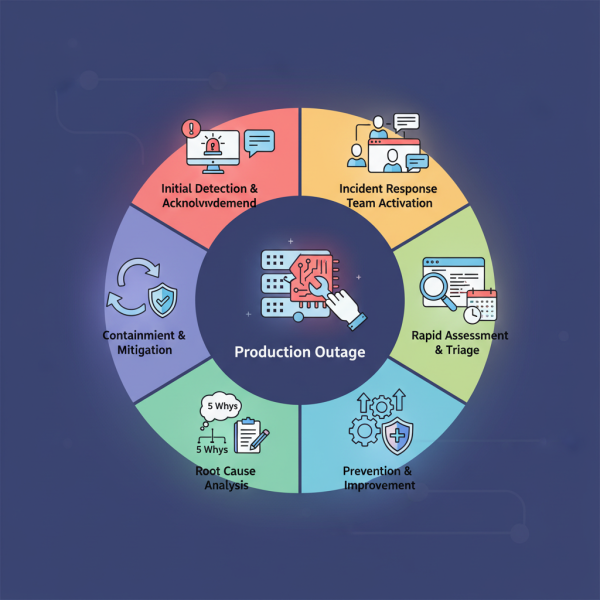
Incident Response StructureRapid Service RestorationRoot Cause AnalysisContinuous ImprovementProduction outages are an inevitable reality in the complex world of live software products. While no one wishes for them, every Software Engineering Manager must be prepared to face them head-on with a clear, actionable strategy. A well-defined incident response playbook is not just a nice-to-have; it's a critical tool for minimizing downtime, preserving user trust, and protecting your company's reputation and bottom line. This article outlines a practical playbook of actions, focusing on swift recovery and methodical root cause identification, designed to guide your team through the storm.
Initial Detection and Acknowledgment
The first critical step in any outage scenario is detection. Modern systems should employ robust monitoring and alerting tools that can automatically identify anomalies and failures. These systems range from application performance monitoring (APM) tools to infrastructure monitoring, log aggregation, and synthetic transaction monitoring. The goal is to detect an issue, often before users even report it.
Once an alert is triggered, or a user report is received, the incident must be formally acknowledged. This involves identifying an Incident Commander (IC), who will be the single point of contact and decision-maker for the duration of the incident. The IC's immediate task is to confirm the outage, assess its scope, and initiate the communication protocol. A quick, initial internal communication should go out to relevant stakeholders, informing them of a potential incident and that an investigation is underway.
Incident Response Team Activation
With an acknowledged incident and a designated IC, the next step is to activate the appropriate incident response team. This typically involves leveraging on-call rotations and escalation policies to bring in the engineers best equipped to diagnose and resolve the issue. Clear, established communication channels are paramount here. This often means setting up a dedicated chat room (e.g., Slack channel) and a video conferencing bridge for real-time collaboration.
- Assembling the Core Team: The IC identifies and brings in critical personnel from relevant engineering teams (backend, frontend, database, infrastructure, SRE).
- Establishing Communication Lines: The dedicated chat channel becomes the central hub for all incident-related communication, updates, and data sharing. The video bridge is for synchronous discussions and complex problem-solving.
- Defining Roles: Beyond the IC, specific roles like a communications lead (for external/internal updates), a technical lead (for deep diving into the issue), and a scribe (to document actions) can be assigned to streamline operations.
Rapid Assessment and Triage
Once the team is assembled, the focus shifts to understanding the problem. This is not yet about finding the ultimate root cause, but rather about gathering enough information to formulate hypotheses and guide initial mitigation efforts. The IC directs the team to quickly gather vital signs and symptoms:
- Review Monitoring Dashboards: Check key metrics for CPU, memory, network, database connections, error rates, and latency. Look for sudden spikes or drops correlating with the outage start time.
- Examine Recent Changes: A significant percentage of outages are triggered by recent deployments, configuration changes, or infrastructure updates. Quickly ascertain what changes were made recently and by whom.
- Analyze Logs: Centralized log management systems are invaluable. Search for errors, exceptions, or unusual patterns that coincide with the incident.
- User Impact Assessment: Confirm which features or services are affected and the extent of user disruption. This helps prioritize recovery efforts.
Based on this rapid assessment, the team investigates initial hypotheses about the potential cause. Is it a database issue? A new code deployment? A network problem? A third-party service dependency failure?
Containment and Mitigation: Bringing Your Product Back Online
The absolute priority during a production outage is to restore service as quickly as possible, even if a permanent fix isn't immediately available. This phase is about containment and mitigation, not necessarily root cause identification. The goal is to reduce user impact and stabilize the system.
Common mitigation strategies include:
- Rollback: Revert recent code deployments to a known good state. This is often the fastest way to resolve issues introduced by new code.
- Failover: Switch to a redundant system, database replica, or a different availability zone/region if your architecture supports it.
- Traffic Redirection/Load Shedding: Temporarily divert traffic, reduce load, or disable non-essential features to stabilize core services.
- Temporary Configuration Changes: Adjust settings, increase resource limits, or disable problematic features temporarily.
- Restart Services: A simple, sometimes effective, first step for certain types of transient issues, though it should be done carefully.
Throughout this phase, the Communications Lead provides regular updates to internal stakeholders and, if necessary, to affected customers. Transparency, even with limited information, is crucial for maintaining trust.
Root Cause Analysis (Post-Restoration)
Once the product is back online and stable, the focus shifts from mitigation to understanding why the outage occurred. This requires a thorough, blameless post-mortem. The aim is not to assign blame, but to identify all contributing factors and learn from the incident to prevent recurrence.
Key steps in Root Cause Analysis (RCA):
- Timeline Reconstruction: Create a detailed, minute-by-minute timeline of events leading up to, during, and after the outage. Include all actions taken by the incident response team.
- Data Gathering: Collect all relevant data – logs, metrics, configuration files, code changes, monitoring alerts, and team communications.
- "5 Whys" or Ishikawa Diagram: Use structured techniques like the "5 Whys" to progressively dig deeper into the causes, moving beyond symptoms to underlying systemic issues. For example, "Why did the service fail?" "Because a new deployment had a bug." "Why wasn't the bug caught?" "Because test coverage was insufficient for that edge case."
- Identify Contributing Factors: Often, an outage is not due to a single cause but a confluence of factors, including technical issues, process gaps, and communication breakdowns.
- Documentation: Prepare a comprehensive post-mortem report that summarizes the incident, its impact, the actions taken, the identified root cause(s), and, critically, a list of actionable preventative measures.
Prevention and Improvement
The insights gained from the RCA are invaluable. This final phase translates those learnings into concrete actions to improve system resilience, observability, and incident response processes. It's where the investment in an outage pays off in long-term reliability.
Examples of preventative actions:
- System Enhancements: Implement fixes for identified bugs, improve architectural resilience (e.g., add redundancy, introduce circuit breakers), optimize resource allocation.
- Monitoring and Alerting Improvements: Close gaps in monitoring, refine alert thresholds, add new dashboards for better visibility into critical components.
- Process Refinements: Update deployment procedures, enhance rollback mechanisms, improve incident communication protocols, conduct regular drills.
- Knowledge Sharing: Disseminate lessons learned across engineering teams to prevent similar issues from arising in other services.
- Playbook Review: Regularly review and update the incident response playbook itself based on real-world incident experiences.
Summary
Effectively managing a software production outage requires a disciplined, structured approach. From the moment an incident is detected, through rapid assessment, swift service restoration, and methodical root cause analysis, every step is critical. By fostering a culture of preparedness, leveraging clear communication, and committing to continuous improvement, Software Engineering Managers can transform disruptive outages into valuable learning opportunities, ultimately strengthening their products and teams.
Comprehension questions
 What is the primary goal during the initial phase of a production outage, even before identifying the root cause?Beyond immediate restoration, what key activities are involved in the What role does structured communication play during an ongoing incident, and what are its key components?
What is the primary goal during the initial phase of a production outage, even before identifying the root cause?Beyond immediate restoration, what key activities are involved in the What role does structured communication play during an ongoing incident, and what are its key components?